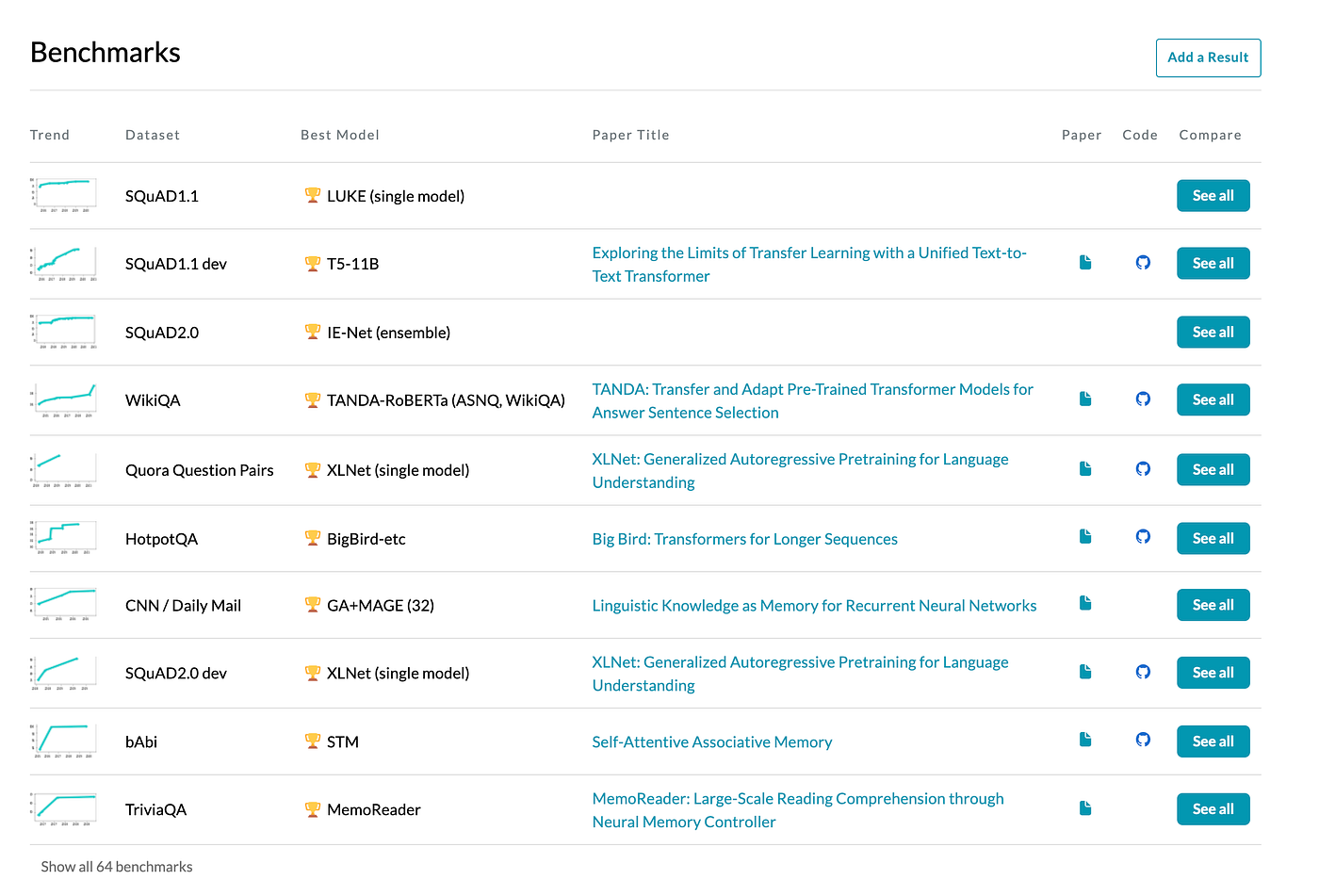
XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 29 maio 2024

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
ACL Best Paper: Tricky Stanford DataSet Adds Questions That Don't
Understanding Semantic Search— (Part 1: Introduction to Machine

LSP Dataset - Machine Learning Datasets

MLQA Dataset Papers With Code
GitHub - pallavrajsahoo/Question-Answering-System-with-SQuAD

PDF] CodeQA: A Question Answering Dataset for Source Code
Dmitry Kobak on X: Really cool work by Pierre Lambert et al

Sensitivity to parameter choices on the Kazer et al.⁶ dataset and

PDF] VulBERTa: Simplified Source Code Pre-Training for
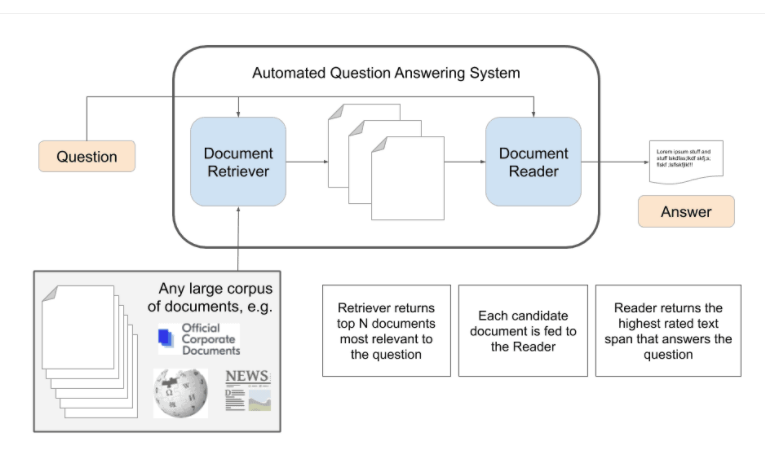
End to End Question-Answering System Using NLP and SQuAD Dataset

NukeBERT: A Pre-trained language model for Low Resource Nuclear

Papers With Code Machine Learning Papers and Code Free Resource

The Quick Guide to SQuAD. All the basic information you need to
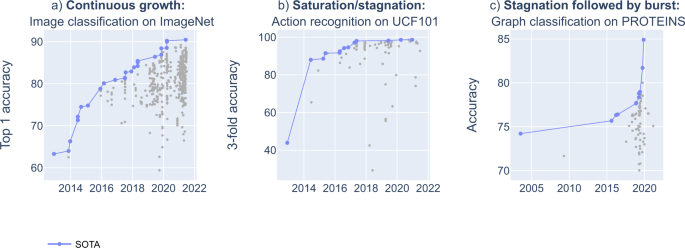
Mapping global dynamics of benchmark creation and saturation in
Recomendado para você
-
 Essential Questions for Small Engines29 maio 2024
Essential Questions for Small Engines29 maio 2024 -
250 TOP I.C. Engines - Mechanical Engineering Multiple Choice Questions and Answers List, PDF, Internal Combustion Engine29 maio 2024
-
 Internal Combustion Engines 2010-2011 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download29 maio 2024
Internal Combustion Engines 2010-2011 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download29 maio 2024 -
 Diesel Engines: Questions and Answers by Wharton, A. J. Paperback / softback The29 maio 2024
Diesel Engines: Questions and Answers by Wharton, A. J. Paperback / softback The29 maio 2024 -
 115 Question and Answers DMV Test (Latest 2022/2023) Download to Score A, Exams Engineering29 maio 2024
115 Question and Answers DMV Test (Latest 2022/2023) Download to Score A, Exams Engineering29 maio 2024 -
 Solved PHYS-48-40278-F20) Assignments Conceptual Questions29 maio 2024
Solved PHYS-48-40278-F20) Assignments Conceptual Questions29 maio 2024 -
 PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES29 maio 2024
PDF) THERMAL ENGINEERING -I UNIT -III SHORT QUESTIONS AND ANSWERS INTERNAL COMBUSTION ENGINES29 maio 2024 -
 SEM Exam - 50 Questions with answers29 maio 2024
SEM Exam - 50 Questions with answers29 maio 2024 -
 ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score29 maio 2024
ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score29 maio 2024 -
 NODE.JS Interview Questions & Answers - CodeWithCurious29 maio 2024
NODE.JS Interview Questions & Answers - CodeWithCurious29 maio 2024

você pode gostar
-
 backrooms level 999: the Island in the void : r/backrooms29 maio 2024
backrooms level 999: the Island in the void : r/backrooms29 maio 2024 -
 Using Memes in Content Marketing: How to Do It Right29 maio 2024
Using Memes in Content Marketing: How to Do It Right29 maio 2024 -
 Clutch कसे काम करते- मराठीमध्ये Clutch-How does it work -In Marathi29 maio 2024
Clutch कसे काम करते- मराठीमध्ये Clutch-How does it work -In Marathi29 maio 2024 -
 Godzilla, Mothra & King Ghidorah: Giant Monsters All-Out Attack Origin – Mondo29 maio 2024
Godzilla, Mothra & King Ghidorah: Giant Monsters All-Out Attack Origin – Mondo29 maio 2024 -
 Chess champion Magnus Carlsen changes Twitter bio after reaching Fantasy Premier League top rank29 maio 2024
Chess champion Magnus Carlsen changes Twitter bio after reaching Fantasy Premier League top rank29 maio 2024 -
 bleach: Bleach TYBW 'The Battle': Know the release time, date, synopsis for episode 10 & recap of 'The Drop' - The Economic Times29 maio 2024
bleach: Bleach TYBW 'The Battle': Know the release time, date, synopsis for episode 10 & recap of 'The Drop' - The Economic Times29 maio 2024 -
 Crunchyroll to Stream New Live-Action Death Note Show Outside29 maio 2024
Crunchyroll to Stream New Live-Action Death Note Show Outside29 maio 2024 -
 365 jogos dos sete erros - Ciranda Cultural29 maio 2024
365 jogos dos sete erros - Ciranda Cultural29 maio 2024 -
 Netflix's 'One Piece' Debuts to Huge Critical Success - mxdwn29 maio 2024
Netflix's 'One Piece' Debuts to Huge Critical Success - mxdwn29 maio 2024 -
 teens titans the go!29 maio 2024
teens titans the go!29 maio 2024