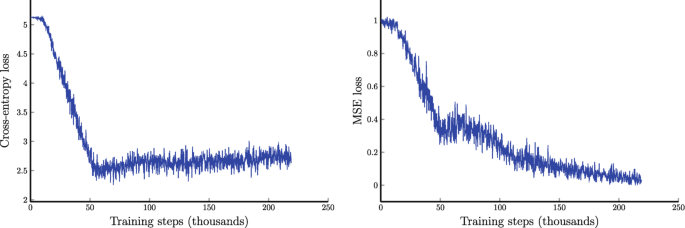
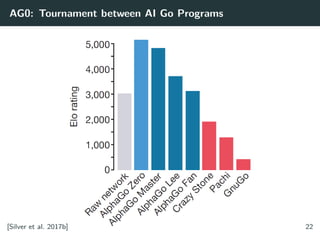
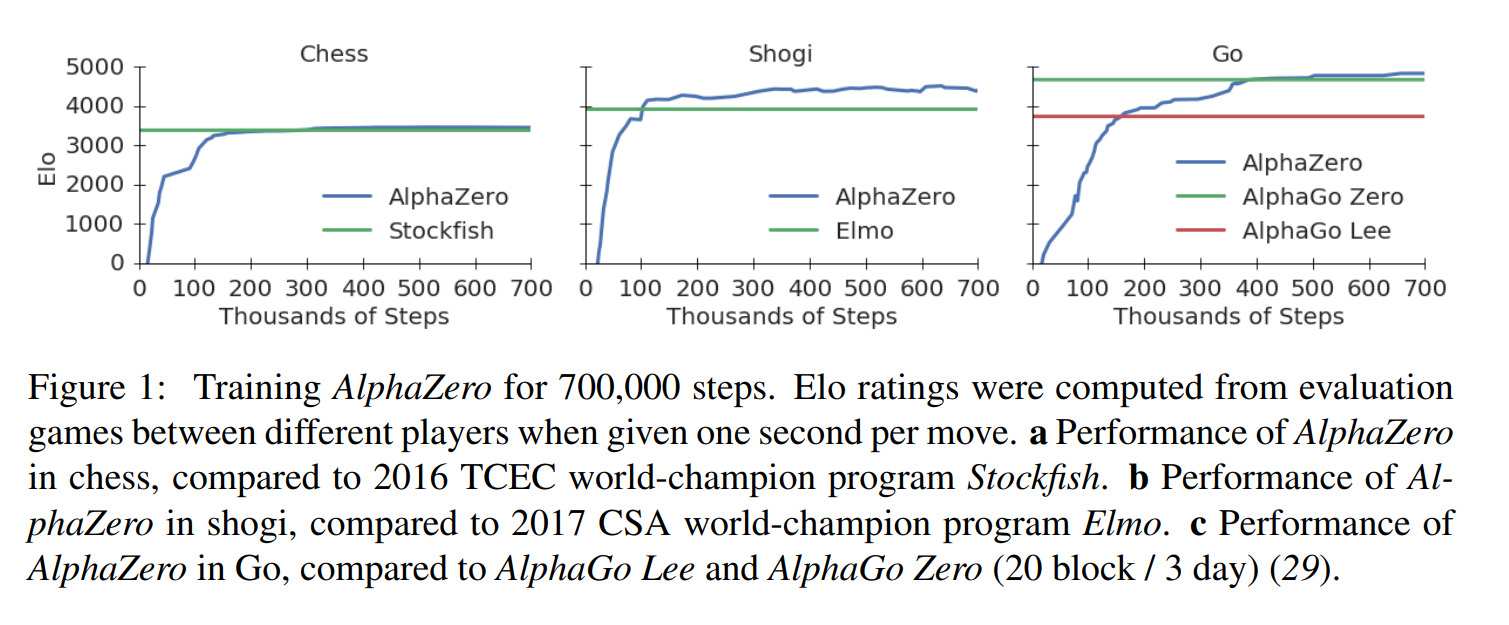
Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Last updated 18 junho 2024

Planning with a Model: AlphaZero
Training AlphaZero for 700,000 steps. Elo ratings were computed from

AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela-zero · GitHub
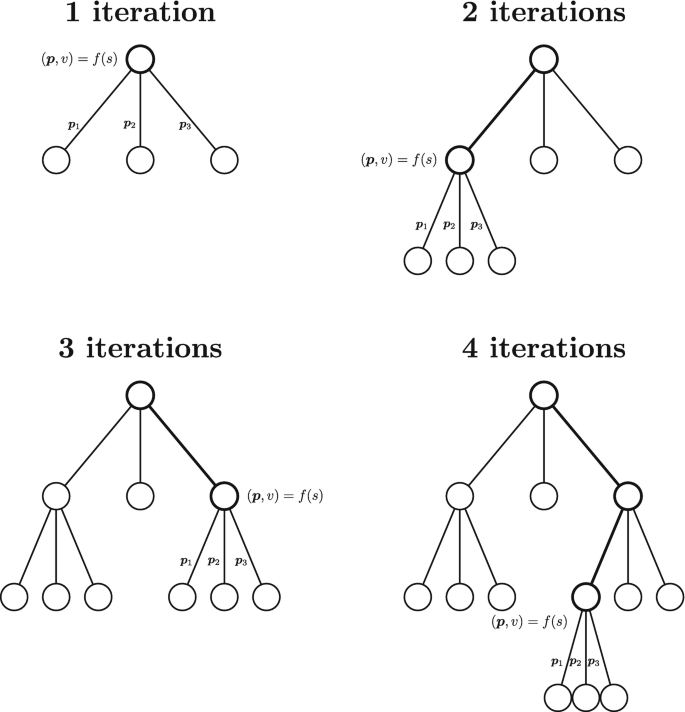
Planning with a Model: AlphaZero
AlphaZero
The future is here – AlphaZero learns chess

Are there any ways to calculate the rating difference between AlphaGo Zero and Leela Zero? · Issue #2576 · leela-zero/leela-zero · GitHub

The future is here – AlphaZero learns chess
When Alpha Zero is making seemingly bizarre moves in chess is it actually predicting what its opponent will do (calculating possibilities), or is it setting up its own attack/defense based on positional
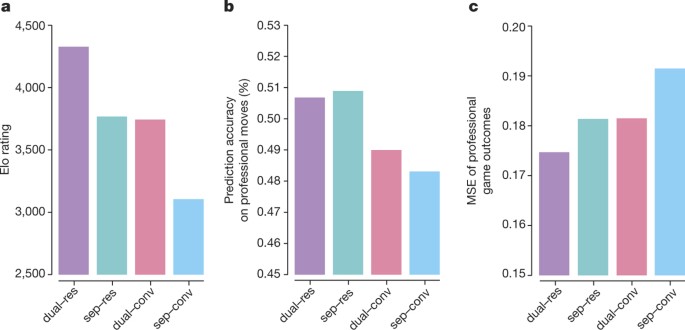
Mastering the game of Go without human knowledge

Checkmate for Traditional Chess? - Nekst-Online

A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan

The future is here – AlphaZero learns chess

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors
Recomendado para você
-
 AlphaZero - Wikipedia18 junho 2024
AlphaZero - Wikipedia18 junho 2024 -
![6 Best & Most Powerful Chess Engines [Ranked] - PPQTY](https://ppqty.com/wp-content/uploads/2023/09/Screen-Shot-2023-09-30-at-1.39.42-AM.png) 6 Best & Most Powerful Chess Engines [Ranked] - PPQTY18 junho 2024
6 Best & Most Powerful Chess Engines [Ranked] - PPQTY18 junho 2024 -
 Tactical, Alpha zero vs Stockfish, again a brilliant display!!18 junho 2024
Tactical, Alpha zero vs Stockfish, again a brilliant display!!18 junho 2024 -
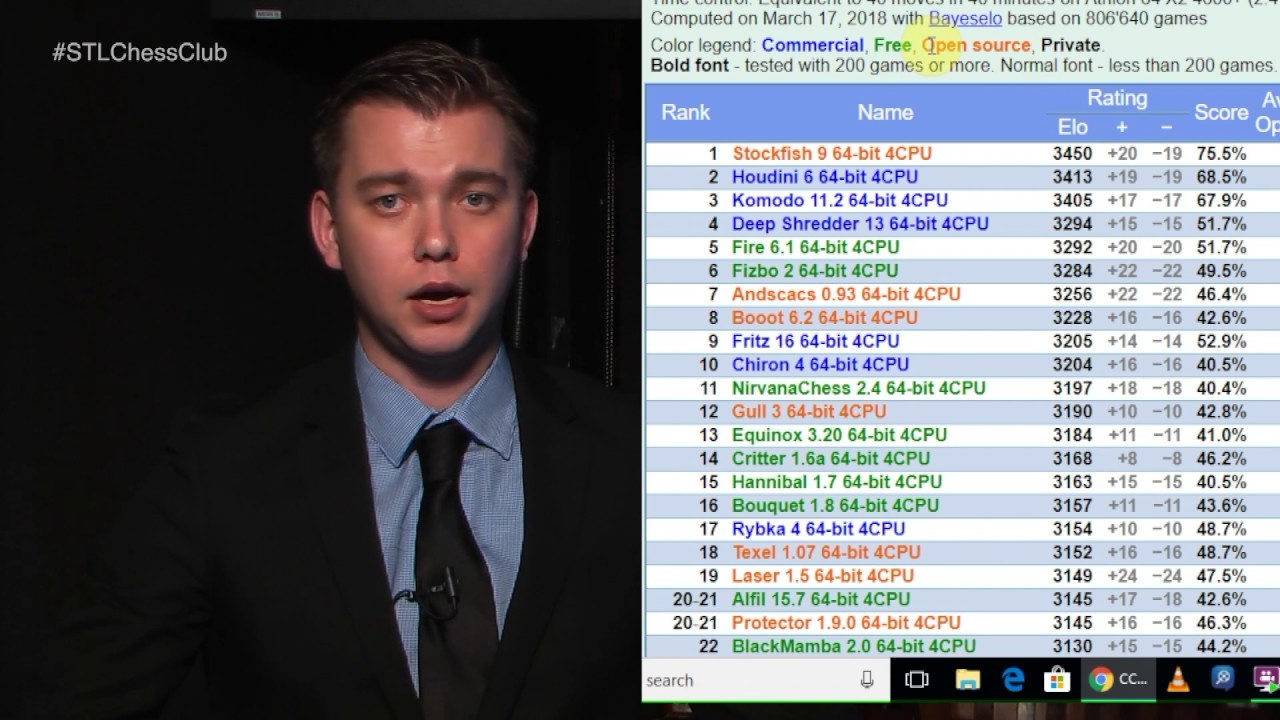 Ultimate Machine War!, AlphaZero vs. Stockfish (Part 1) - IM Vitaly Neimer18 junho 2024
Ultimate Machine War!, AlphaZero vs. Stockfish (Part 1) - IM Vitaly Neimer18 junho 2024 -
 Shedding Light on Chess with the Help of Computers18 junho 2024
Shedding Light on Chess with the Help of Computers18 junho 2024 -
 AlphaZero vs Stockfish 8: A Landmark Battle of Human and Artificial Intelligence in Chess, by David Georgyan18 junho 2024
AlphaZero vs Stockfish 8: A Landmark Battle of Human and Artificial Intelligence in Chess, by David Georgyan18 junho 2024 -
STAL CHESS - Alpha Zero VS Stockfish18 junho 2024
-
 agadmator on X: The Word is Compensation AlphaZero vs Stockfish Enjoy the game and share with friends :) #alphazero #ai #deepmind / X18 junho 2024
agadmator on X: The Word is Compensation AlphaZero vs Stockfish Enjoy the game and share with friends :) #alphazero #ai #deepmind / X18 junho 2024 -
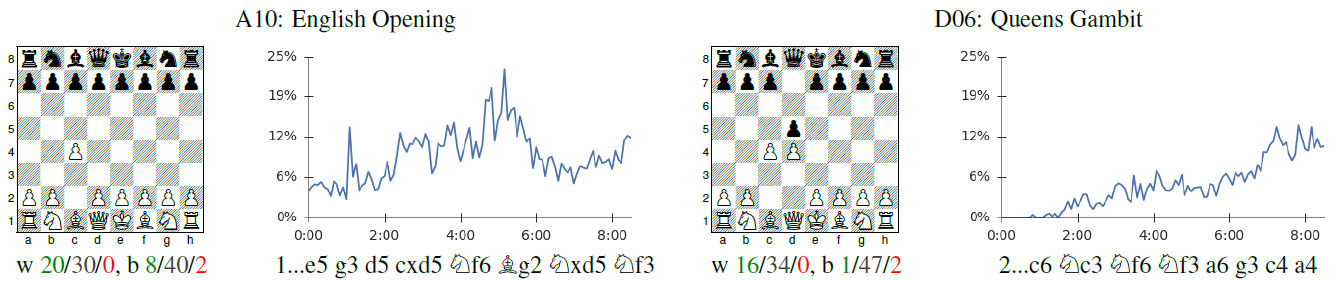
 1.d4, best by test (AlphaZero) • page 1/2 • General Chess Discussion •18 junho 2024
1.d4, best by test (AlphaZero) • page 1/2 • General Chess Discussion •18 junho 2024 -
 TCEC 2019 superfinal to Scid vs PC: STOCKFISH vs Leela - St-Brieuc chess club18 junho 2024
TCEC 2019 superfinal to Scid vs PC: STOCKFISH vs Leela - St-Brieuc chess club18 junho 2024

você pode gostar
-
 The French Defense Revisited18 junho 2024
The French Defense Revisited18 junho 2024 -
 FM-Anime – Fire Emblem Fates Rinkah Cosplay Tattoo Stickers18 junho 2024
FM-Anime – Fire Emblem Fates Rinkah Cosplay Tattoo Stickers18 junho 2024 -
 Vampire Hunters 3 - Theme Roblox ID - Roblox music codes18 junho 2024
Vampire Hunters 3 - Theme Roblox ID - Roblox music codes18 junho 2024 -
 Aslan & The Witch Aslan narnia, Chronicles of narnia, Narnia18 junho 2024
Aslan & The Witch Aslan narnia, Chronicles of narnia, Narnia18 junho 2024 -
A Celebrity MasterChef mystery box challenge rekindles Nick Riewoldt's competitive spirit18 junho 2024
-
 STRIKE DASH IN SONIC 2 jogo online gratuito em18 junho 2024
STRIKE DASH IN SONIC 2 jogo online gratuito em18 junho 2024 -
Memes - Among us memes (4) - Wattpad18 junho 2024
-
 Combine Suppressor - Combine OverWiki, the original Half-Life wiki and Portal wiki18 junho 2024
Combine Suppressor - Combine OverWiki, the original Half-Life wiki and Portal wiki18 junho 2024 -
Vol 5 Illustrations #kagenojitsuryokushaninaritakute18 junho 2024
-
 EA Sports FC 24 Evolution - How does it work in Ultimate Team?18 junho 2024
EA Sports FC 24 Evolution - How does it work in Ultimate Team?18 junho 2024


